It’s been a while since I’ve done one of these. One of the things I’ve realised is that learning outside of the 9 to 5 and normal life is HARD. But despite having some breaks due to increased workload and/or busy months containing friends 30ths, weddings and stag dos – I still found myself wanting to come back and finish the course. After 5months of on and off learning I’m very proud to say that I DID IT!
I am now the proud beholder of the Data Science IBM Professional Certificate (well it’s on my LinkedIn page in digital form) and I genuinely feel like finishing the course has given me a new level of motivation and excitement to learn more. I feel like completing this course has given me the foundations to kick-on and focus on the areas I really want to get into – AI Development and AI Engineering.
Honest Thoughts on the IBM Data Science Professional Certificate
I have learned an awful lot from completing this course. Some of the topics can seem tiresome and sometimes the format of multiple 5-7min videos one after another can be gruelling to sit through. BUT… I really think that the combination of videos and then guided labs to cement what has been discussed really worked for me. I learn by doing and so the combination of labs and projects really kept me going!
Overview of What I’ve Learned
To give an overview of how much I have learned from completing this course I wanted to give a brief overview of the final project that I completed:
- The aim of the project was to build a predictive analytics platform for SpaceY (a new competitor to SpaceX) to estimate the success of Falcon 9 first-stage landings.
- Using SpaceX API data, Wikipedia records, and geospatial processing, I built a classification pipeline and interactive dashboard.
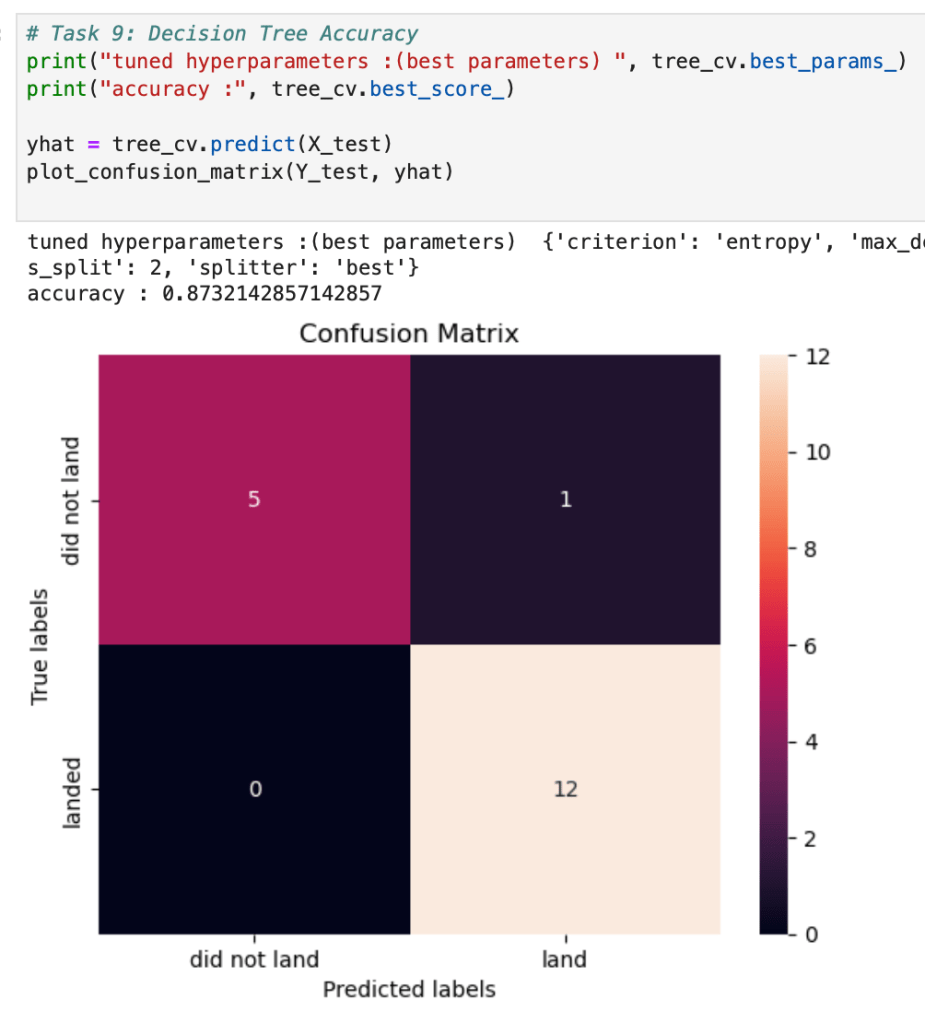
- The Decision Tree classifier yielded the highest accuracy (87.5%) and serves as a deployable model for pre-launch planning.
If someone had told me 5months ago that I would be able to do the above I would have laughed at them! Breaking down what I did in a little more detail:
- Data Acquisition & Integration
- Launch and rocket metadata ingested from SpaceX’s public API and complementary Wikipedia records.
- The SpaceX API provided structured JSON data on past launches, including rocket specifications, payload details, launchpad info, and core performance.
- Wikipedia pages were scraped to supplement landing outcomes and other contextual mission information.
- Geospatial data was enriched using reverse geocoding to calculate proximity to coastlines, railways, highways, and cities using geodesic formulas.
- Data Wrangling & Feature Engineering
- All missions not involving the Falcon 9 rocket were excluded to ensure model focus and consistency.
- Key features were extracted and flattened from nested JSON fields: payload mass, orbit type, booster version, launch site, and landing type.
- Payloads and cores, originally lists of dictionaries, were mapped to extract the primary element.
- All categorical variables were one-hot encoded, and continuous variables were scaled using StandardScaler.
- Outcome labels were binarized into successful (1) and failed (0) landings.
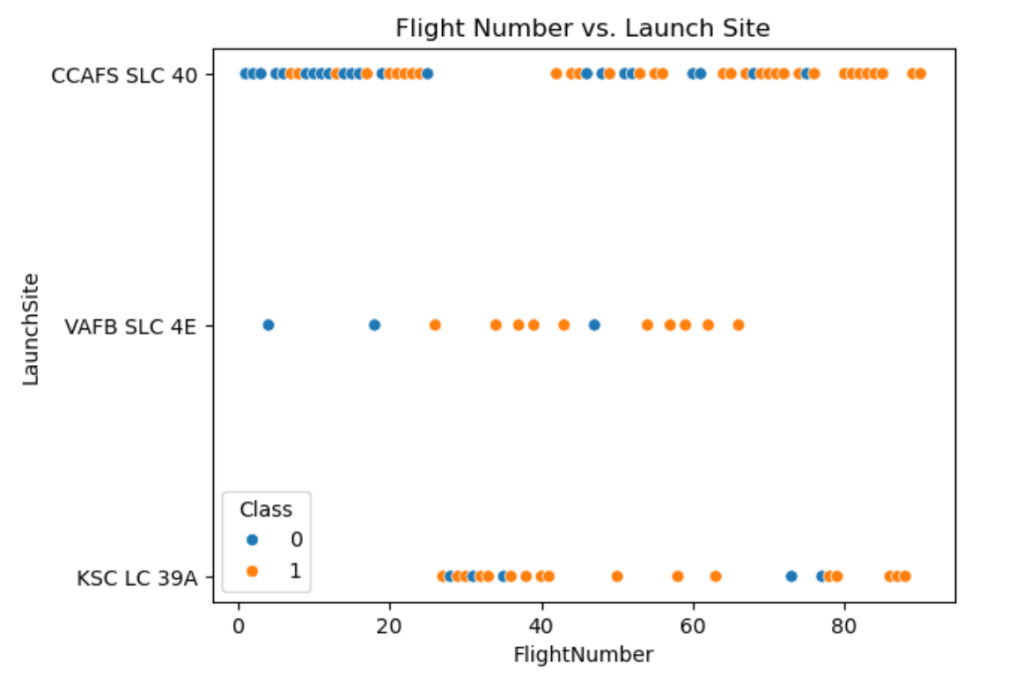
- Exploratory Data Analysis (EDA)
- Using Plotly, we visualized relationships between payload mass and landing outcomes, orbit types and success probability, and site-level performance.
- A range slider in Dash allowed dynamic filtering by payload mass.
- SQL queries were used to:
- Identify the boosters with the most launches
- Calculate average payload per customer (e.g., NASA, SES)
- Determine the first successful landing on a ground pad or drone ship
- These queries were executed using a local SQLite connection integrated within Jupyter.
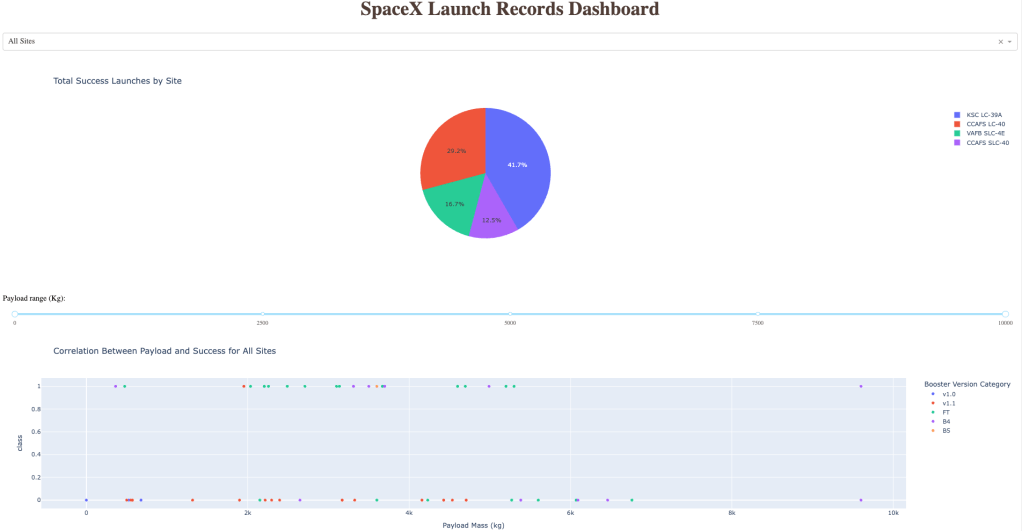
- Interactive Dashboard Development
- A full Plotly Dash application was built to allow non-technical stakeholders to explore the dataset interactively
- The dashboard included dropdowns for orbit type and launch site, payload sliders, and updated pie and scatter plots based on inputs.
- Predictive Modeling & Evaluation
- We tested four supervised classification models:
- Logistic Regression (baseline model)
- Support Vector Machine (non-linear classification)
- K-Nearest Neighbors (local density)
- Decision Tree (interpretable, rule-based model)
- Hyperparameter tuning was performed using GridSearchCV with 10-fold cross-validation.
- Accuracy and confusion matrices were used to compare models, and all results were validated on hold-out test sets.
- We tested four supervised classification models:
GitHub Link to the project: https://github.com/SalvyB123/SpaceY-Capstone-Project/blob/main/SpaceY%20Capstone%20Project.ipynb
Would I recommend the course?
If, like me, you have an interest in the technical side of AI and want to gain a foundational skillset to build upon – absolutely. If you have studied data science at university or work in data science day-to-day, it’s most likely going to be too easy for you!
What’s next?
There are 2 more certificates I want to complete before trying to build out a portfolio of work:
- IBM AI Developer Professional Certificate
- IBM AI Engineering Professional Certificate
I am feeling more motivated than ever to keep progressing – so I am hoping I complete the next one in a shorter timeframe!
Thanks so much for reading and please leave a comment if you’ve made it to the end! Any feedback or thoughts would be greatly appreciated!





Leave a comment